

Summary - Releasing software daily doesn't mean sacrificing quality. Learn the 15 strategies and protocols we use at Klipfolio to balance speed with excellence in continuous delivery.
Our team at Klipfolio is often asked: "How do you release quality software to production every day?" In this post, I'll share the strategies and protocols we use to balance speed with excellence.
It comes down to following a deliberate series of practices. Here's what we do:
1. Produce small, shippable increments and improvements

Small changes are easier to quality-check than large ones. That's why we break work into tiny increments.
This represents a shift in how software gets delivered. Gone are the days of massive releases every quarter. We ship small chunks of code every day. The code may or may not be exposed to users, but smaller changes mean lower risk and faster feedback loops.
We often plan a launch day for a major feature, but we ship most of its components in small increments beforehand. Using feature switches (see item 12), deciding when to expose the feature to customers becomes a business decision rather than a technical one.
2. Define the development process steps
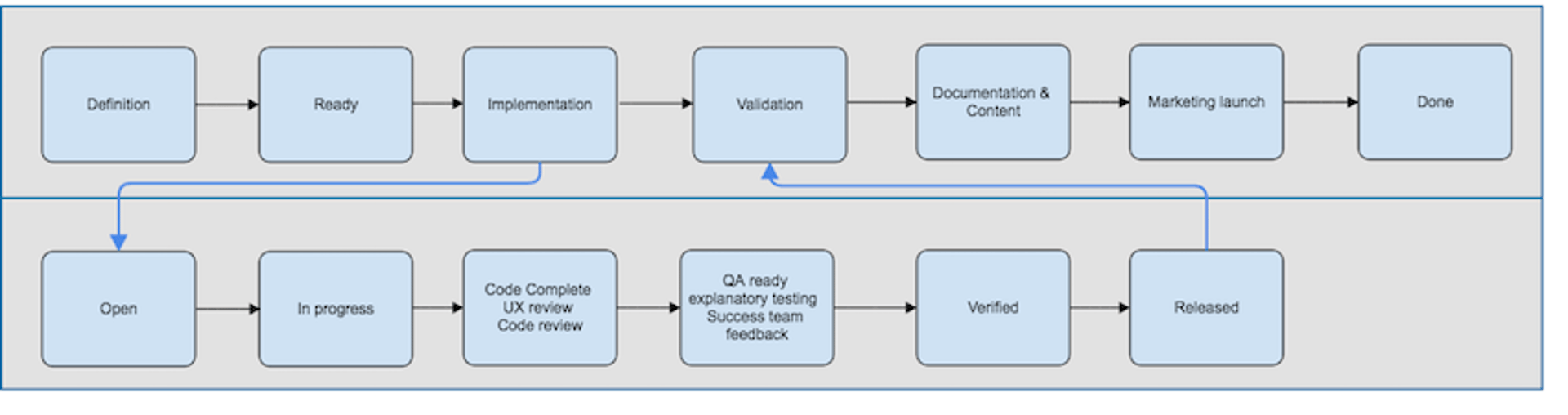
A defined development process makes it easier to track work and catch issues early.
We use an issue tracking system where every code change is tied to a work item and flows through a well-defined set of steps. These steps—including peer reviews, UX reviews, and customer success reviews—ensure code meets a high-quality bar before reaching production.
3. Use work item templates

Templates help teams maintain consistent standards. Each user story and code change includes:
- User story: Defines the core requirement from the user's perspective
- Acceptance criteria: Details the requirement and edge cases
- Quality checklist: Confirms all development process steps (such as automated tests) were completed
4. Use branches and shippable head-of-code stream
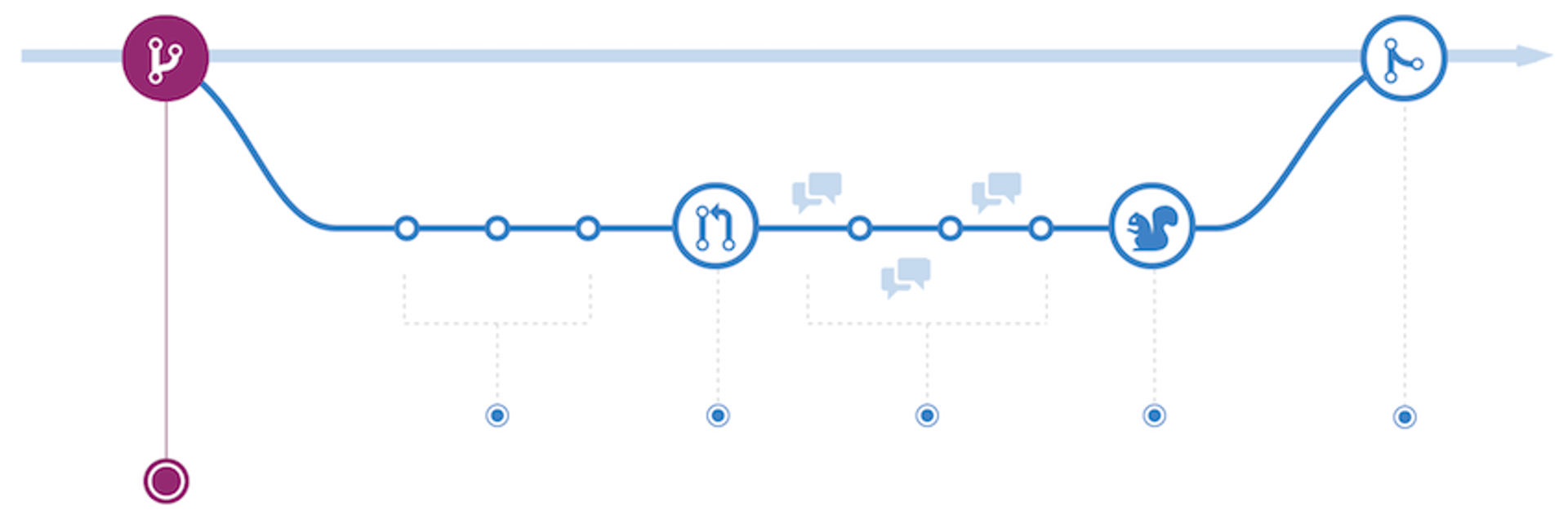
Code branches reduce risk and improve quality when used properly. Protect your main branch at all costs.
We follow GitHub Flow as our branching strategy. It relies on creating a branch for every change. The key is avoiding long-lived branches and maintaining small, shippable increments (as noted in item 1).
Your main branch must always be shippable. This means your continuous integration build on the main branch must always pass. Keeping it healthy is the team's top priority. A broken main branch blocks releases and urgent hotfixes, which can delay critical fixes to production issues.
5. Incorporate continuous integration into your development process
Continuous integration is the backbone of any deployment pipeline and essential for high-quality software.
We run CI builds for every branch and for the main branch. When developers create a new branch, our CI system automatically detects it and starts running tests, including merging the main branch to identify integration issues. When a branch merges into main, we run CI again. Keeping that build green is everyone's priority.
Our CI builds include automated tests and static analysis, which we cover in the next items.
6. Use test automation

Test automation is essential for quality-driven development, yet many teams skip it.
I cringe when I hear: "We need to move faster—there's no time for automated tests" or "We'll write tests after we ship." These mindsets ignore why automated tests matter.
Write automated tests because:
- You save time and deliver high-quality software
- You avoid running the same repetitive tests manually, cutting costs
- Fixing bugs early costs far less than fixing them after launch
- Introducing regressions can damage your brand and customer trust
Automated tests typically fall into three categories:
- Unit tests (written by developers)
- Integration tests
- Functional tests
Unit tests are cheaper to write and maintain, so prioritize more unit tests and fewer integration and functional tests.
7. Use static analysis and automated code reviews

Automated static analysis tools improve code quality and teach best practices.
Tools like FindBugs and Lint catch issues before they reach production. They help developers learn best practices, avoid bugs and security vulnerabilities, and maintain consistency.
When adopting these tools, ensure developers get in-context feedback in their IDE or can run them locally. Also run the same analysis on every code commit. Developers shouldn't see different results locally than in your CI system—that creates frustration and erodes trust in the process.
8. Make code reviews mandatory

If you adopt only one item from this list, choose code reviews. They're one of the most effective ways to improve code quality and team craftsmanship.
Code reviews improve design, catch bugs, mentor junior developers, and share knowledge. You can pair developers before code is written and start design discussions early.
Use tools that make reviews easy. Inline commenting and threaded discussion are critical. We use GitHub Pull Requests, and it works well for us.
Culturally, developers must see code reviews as equally important as writing code. Unfortunately, too many teams treat reviews as chores. If features are rewarded more than thorough reviews, the process won't deliver results. Invest in a culture where reviews are valued.
9. Include teams from user experience, customer success, and product in the review process

Beyond the development team, UX, customer success, and product teams should monitor feature status.
Depending on the feature, we involve these teams and gather their feedback as part of verification. The UX team helps refine the user experience before launch. Even when development matches UX specs exactly, real usage often reveals opportunities to improve.
Customer success teams provide invaluable input because they know how customers actually use the product. They remind us that customers don't always use software as we expect—and that's often where the best insights come from.
10. Use canary releases
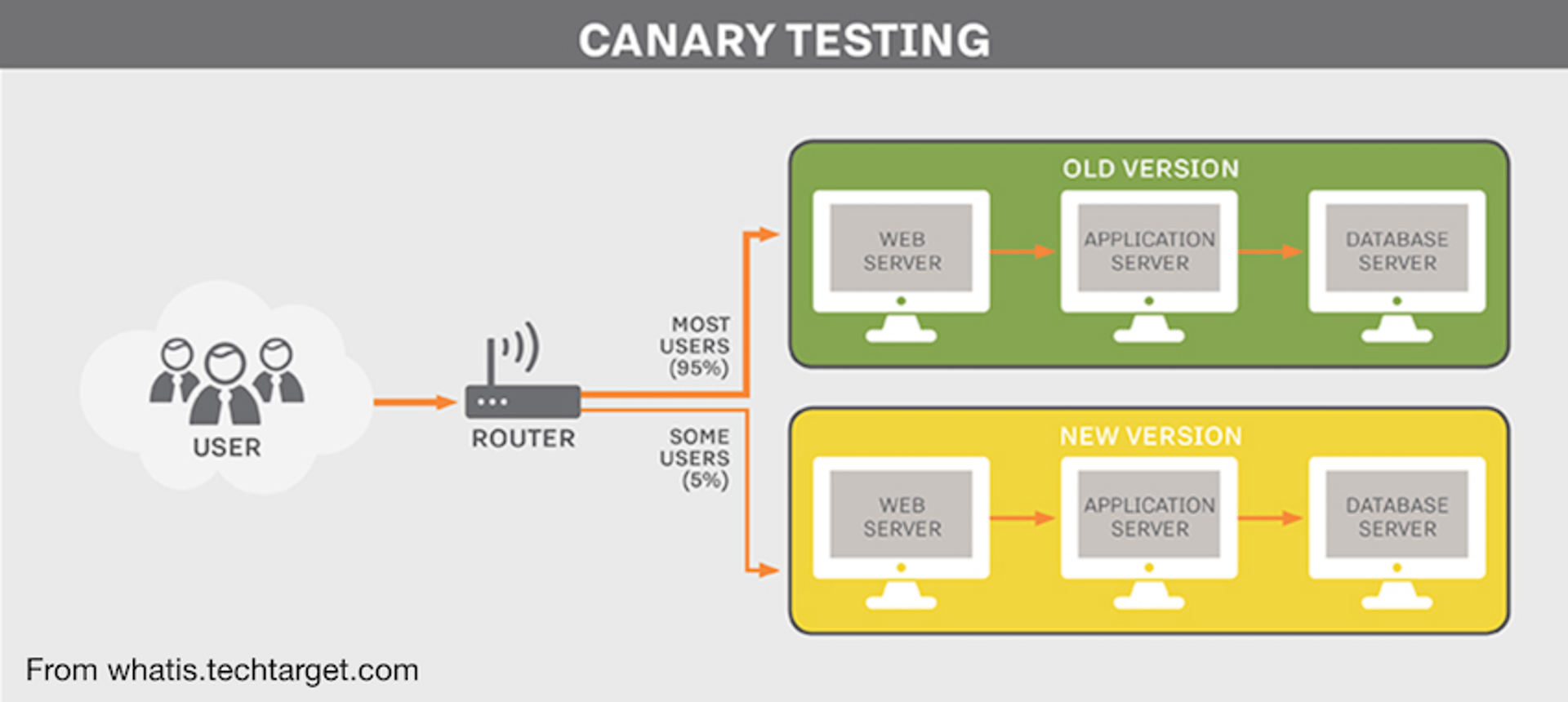
We deploy releases internally for about two hours before releasing to the public.
When changes merge into the main branch, they're first deployed to servers used only by our internal team. People build dashboards, investigate customer issues, and demo the product during this window. If anyone spots issues, they report them immediately through our internal messaging tool.
While we'd prefer issues never surface at this stage, this process has saved us from shipping embarrassing bugs to the entire customer base many times. It's worth every minute.
I highly recommend this step, especially if your automated test coverage isn't comprehensive. This short period of implicit testing is remarkably effective.
11. Use a crowdsourcing quality assurance platform
Crowdsourcing QA platforms let you run large regression test suites quickly.
These platforms distribute test suites to a pool of manual testers who run them in parallel. Results are aggregated and sent to your CI tools (like Jenkins) or messaging apps (like Slack).
Using such platforms helps you:
- Complement automated tests with manual testing for visual validation and user experience checks
- Run manual tests quickly since they're distributed and executed in parallel
- Free your QA team from repetitive regression testing so they can focus on exploratory and in-depth testing
12. Use feature switches often

Feature switches let you turn features on and off for targeted customer groups. They increase quality and reduce risk before full exposure.
Deploy a feature all the way to production to observe its impact without exposing it to all customers. This works for risky features and for features in development for months but not yet ready for release.
13. Accept the risk
No process is risk-free, and mistakes are inevitable. In fact, here's the truth: If you aren't making mistakes, you aren't moving fast enough.
Although we follow all the steps above, deploying to production daily still carries risk. We accept it and learn from it. Every time a problem arises, we step back and improve our process.
14. Perform post-release monitoring
Post-release monitoring lets us handle problems quickly.
While we accept risk, we're ready to respond. We use various tools to monitor production:
- ELK stack for log monitoring
- New Relic for performance and client-side error tracking
- Internal monitoring and self-healing bots to catch issues automatically
15. Have hotfix and rollback processes in place
Have a clear process to fix mistakes or roll back to previous versions.
Getting the hotfix and rollback process right—and making it as simple as possible—is as important as making the release process easy. You must be able to rollback a release with a single click.
The process should be automated and reliable so it works flawlessly, even during a crisis. Make sure multiple team members know how to use it, not just one person.
Final words on ensuring quality in continuous delivery
Releasing daily doesn't mean rushing code to production. While we monitor cycle time weekly to find improvement opportunities, quality remains one of our highest priorities.
Use the right tools and processes to deliver high-quality software consistently. Speed and excellence aren't opposites—they're partners when you have the right foundation.
See also:
Related Articles
Anatomy of a great API
By Danielle Hodgson — January 21st, 2026
Klipfolio Partner How-To #1: Duplicating dashboards across client accounts
By Stef Reid — November 27th, 2025
Klipfolio Partner How-To #2: Company Properties can simplify client set-up
By Stef Reid — November 26th, 2025
