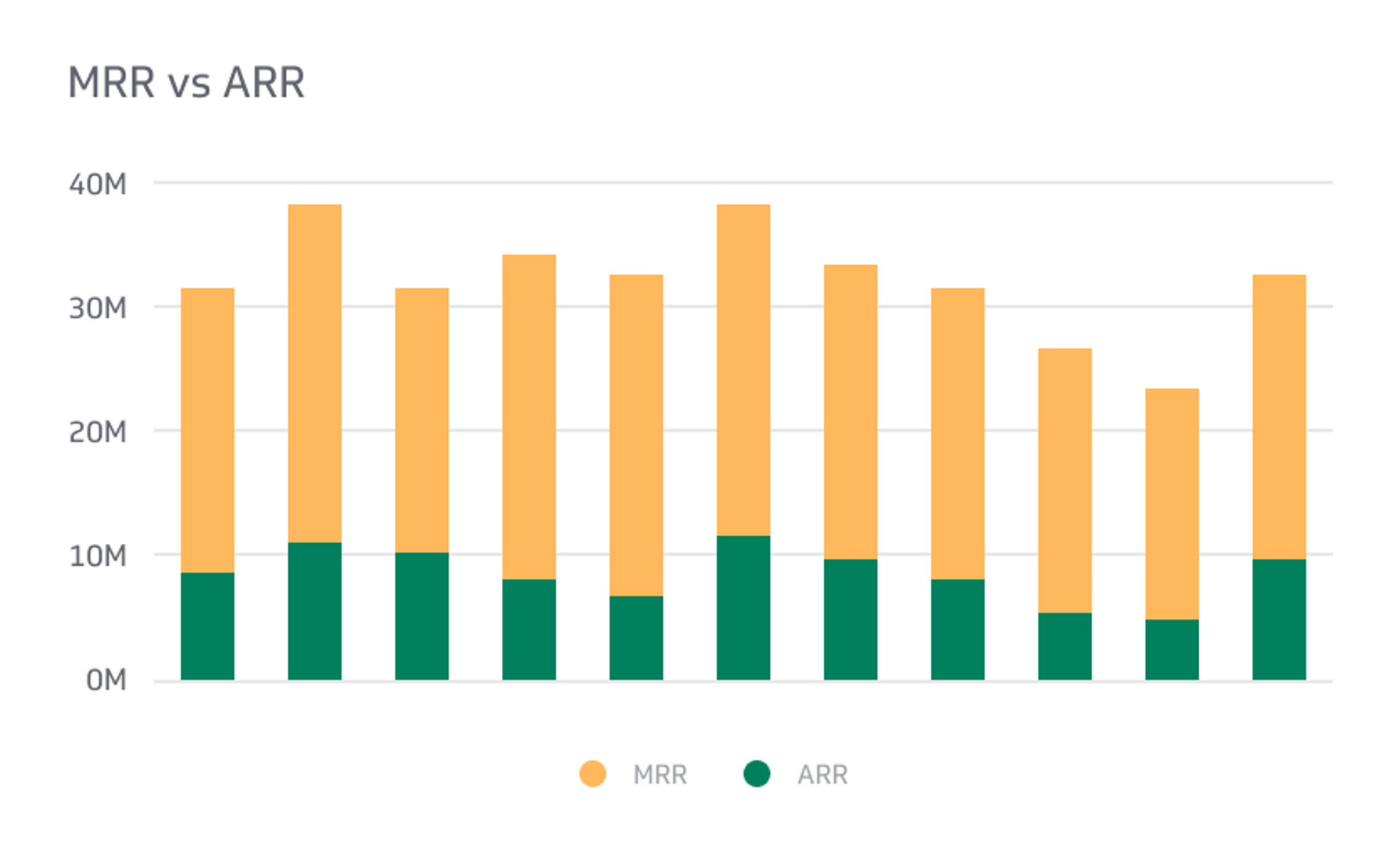
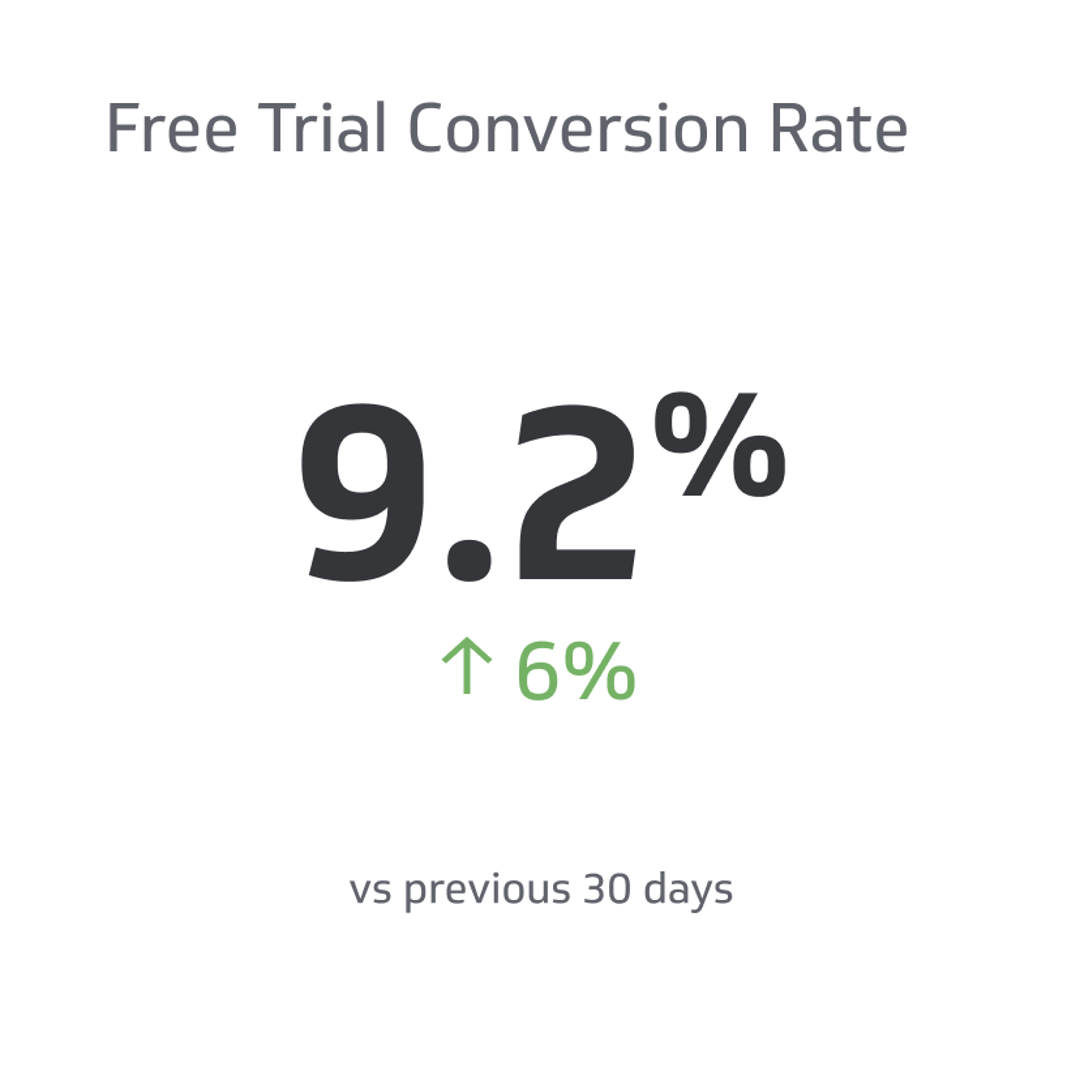
Free Trial Conversion Rate
The number of customers who opt for a paid product from the free version.
Track all your SaaS KPIs in one place
Sign up for free and start making decisions for your business with confidence.
Data is integral to the function and scaling of any organization.
There are many crucial key performance indicators (KPIs) that people use to assess the success of a business. From email click-through rate to cost per customer, the many metrics involved in running a SaaS business are too many to count.
You might wonder how to cut through the noise, struggling to determine which metrics matter and which don’t.
As a SaaS company, the free trial conversion rate is among the most important metrics you can use to assess the viability of your marketing strategies.
A free trial conversion rate lets you know how many of your customers opt for the paid version of your product—and it can teach you a lot.
Use this guide to learn everything you need to know about free trial conversion rate—and how to optimize yours.
What Is a Free Trial in SaaS?
When you launch a new product, you need to find a way to get customers to try it.
Without a free trial, most people will not be willing to try your product because they won’t be able to tell what it does for them.
Enter the free trial. A free trial allows customers to test your product for a period. It follows the principle of “show, don’t tell.” Allowing customers to try your pro will enable them to grasp your value proposition.
There are advantages and disadvantages to free trials. Still, most experts agree that free trials can dramatically help to boost revenue by enticing prospective clients to test your product or service.
One study suggests that free trials are the most effective strategy, contributing to 66% of B2B conversions.
The above number represents the conversion rate—the number of customers who opt for a paid product from the free version. Conversion rates differ depending on many factors, including the type of trial used.
Types of SaaS Free Trials
There are several different types of free trials within the SaaS industry. Each offers a different conversion rate and different benefits and drawbacks. Consider the following factors.
Unlimited Free Trial
An unlimited free trial grants the user access to all of your products and services for free—most last a determinate period—two weeks, for example.
Limited Free Trial
In a limited free trial, your customer has access to one or more products for free. They may be able to access the lowest plan, for example, or only perform a certain number of actions.
These free trials may have a given period or may continue indefinitely, allowing the user to continue using the accessible version of your product without having to pay.
The idea behind a limited free trial is that it incentivizes customers to opt for the pricier version of your product once they’ve had a taste.
Opt-In Free Trial
Free trials can also differ based on the transition to the paid product. An opt-in free trial, for example, is when the user does not have to enter a credit card number to use the accessible version of your product.
At the end of the free trial, the plan ends, and they are free to pay for the product if they choose, rather than being automatically billed.
Opt-Out Free Trial
Opt-out free trials require a credit card number before the problem starts.
By the end of the trial, the client is charged for the paid version of the product automatically.
While opt-out free trials occasionally boost conversion rates, opt-in tests are more effective.
B2C Free Trials
B2C companies cater directly to consumers. They typically have more extended free trial periods of 30 days on average.
They choose to do so because consumers may need more time to determine if the value proposition applies to them.
B2B Free Trials
B2B businesses cater to other companies, and their free trials tend to be shorter (two weeks on average) and boast higher conversion rates.
This is because businesses tend to solicit products for a specific reason or to fulfill a need, so they are more likely to spend money on them upon completion of the free trial.
What Is a Free Trial Conversion Rate?
Your free trial conversion rate is the rate at which users opt for the paid product from the free trial.
This number is taken by subtracting the percentage of users who did not opt for the paid product from the total number of users who tested the free product.
You can also determine the free trial conversion rate by dividing the number of trial users by the number of trial-to-paid users.
This number tells you how many customers enjoyed your product and chose to use it following the free trial.
Opt-Out vs. Opt-In Free Trial Conversion Rates
If you use an opt-out free trial structure, it can be harder to determine the efficacy of your free trial as a marketing strategy.
Because opt-out trials require users to consciously remove their credit card information, many inadvertently collect the charge for the product, only to cancel the service later.
As a result, you won’t know how many users consciously opted for your product—and the data won’t be beneficial.
As a result, it’s better to use an opt-in free trial structure to allow people to test the product without risk.
Clients are also more likely to take advantage of such a trial structure, as it does not present any liabilities for them.
Limited vs. Unlimited Free Trial Conversion Rates
Both limited and unlimited free trials have specific benefits and drawbacks when it comes to conversion rates.
While unlimited free trials can allow customers to try all of your products, they are easier to hack than other systems, as users may create multiple accounts or try to take advantage of the system.
Alternatively, limited free trials limit the possibility of abuse. Still, they may also restrict your market size to those users who are only interested in one feature or product in particular.
As a result, conversion rates vary between limited and unlimited free trials, and both offer advantages and disadvantages.
B2B vs. B2C Free Trial Conversion Rates
B2B companies tend to have higher conversion rates than B2C free trials.
The higher conversion rate occurs because other businesses are more likely to seek out software that fulfills a specific need and, thus, are more likely to pay for them.
Most companies choose between these types of free trials based on their consumer base.
Why Are Free Trial Conversion Rates Important?
Free trial conversion rates offer plenty of actionable data—and in SaaS and business, data is everything.
Your free trial conversion rate lets you know what percentage of your consumer base is interested in and willing to pay for your product.
If you use an opt-out trial, you can determine how many consumers responded to your value proposition and adjust your marketing strategies or product development accordingly.
The higher your free trial conversion rate, the more likely you are to earn revenue from the product—and the more likely you are to scale your business.
Additionally, your free trial conversion rate lets you know how many pre-qualified leads you have. When you offer a free trial, you can collect customer data, and you know that these users are willing to pay for your product.
The more pre-qualified leads you have, the easier it will be to get the word out about future products and make more sales.
Lastly, your free trial conversion rate gives you access to valuable customer demographics. When consumers begin using your product, they will sign up and provide valuable data about their demographics and interests.
You can harness this opportunity to learn more about the people your company caters to and to develop more relevant products and marketing strategies.
You can also use the free trial conversion rate to determine the efficacy of your free trial structure. If your free trial subscriptions and conversions are low, you may need to change the parameters of the free trial itself.
Remember that metrics work best when evaluated against one another. For this reason, it’s best to assess the free trial conversion rate in tandem with other metrics like retention.
For example, you might have a scenario where you get many free trial conversions, but users quickly stop using your product. Keeping an eye on your retention rate can alert you to this phenomenon.
How To Calculate Free Trial Conversion Rate
Your free trial conversion rate calculates the number of customers who opted for the paid version of your product from the free trial.
You can also determine the free trial conversion rate by dividing the number of trial users by the number of trial-to-paid users.
The equation is:
FCR = number of trial-to-pair users/number of trial users in total
You can also calculate your free trial conversion rate by subtracting the number of unpaid users from the total number of people who took advantage of the free trial.
With a free trial, you can access more data to learn new things about the customer base as a whole.
Factors Affecting Free Trial Conversion Rate
Many factors may influence your trial conversion rate. To better understand how you might adjust the parameters of your free trial, consider the following.
Trial Length
The time length of your free trial might impact the extent to which users opt for your product—most free trials last between one week to 60 days. Longer tests typically allow your customers to spend more time getting to know the product, making them more likely to purchase it.
Features
The features of your product are crucial in determining your free trial conversion rate. While an unlimited free trial can allow users to try out more things, they might neglect to pay for the priced product.
On the other hand, a limited trial can entice consumers to try different features similar to the one they got to try.
Customer Support
During the free trial period, one of the things that consumers pay attention to is customer support. For this reason, it’s essential to offer robust customer support options to consumers—whether they are paid customers or remain on a free trial.
Brand Awareness
Simple brand awareness can affect your free trial conversion rate because consumers may be unaware of the free trial option.
You can raise your conversion rate by marketing the free product more aggressively.
Ease of Use
When users try your product, they are looking for an interface that is intuitive and a design that is familiar to them.
They might not opt for the paid version of your product if they have deemed the free version too difficult to use.
For this reason, it’s essential to ensure your free features are accessible and relevant to your customer base.
Pricing
If your prices are relatively high for your consumer base, users may opt for the trial and neglect to pay once the trial has ended.
Pricing can also influence consumers because a more expensive product is likely to be more desirable as a free trial, and users will want to take advantage of this opportunity.
What Is a Good Free Trial Conversion Rate?
Your free trial conversion rate will depend upon the above factors.
A good FCR for an opt-in trial is 8.2%, while the consensus for an opt-out trial is an average of 2.5%.
Remember that you should evaluate your free trial conversion rate alongside metrics like CAC and LTV ratio.
How To Boost Your Free Trial Conversion Rate
Improving your free trial conversion rate takes time and effort—both of which you may not have.
Thankfully, there are industry-leading, research-backed tips you can draw from to make the most of your free trial option.
Consider the following before assessing your free trial conversion rate.
Improve User Friendliness
Many users are testing out your product to determine if it is accessible to them to use.
For this reason, they’ll pay special attention to the user interface and design of your free trial product or service.
Ensure that the free product is just as—if not more—intuitive for users to understand, and continue to work on fixing bugs and comprehension issues.
Improve OnBoarding
On the same note, users often need help to understand your product.
For this reason, it’s essential to have a robust onboarding protocol and plenty of customer service options for your new users to take advantage of.
Having access to consistent support is an incentive for your new users to continue working with your company, and it lets them know that you care about their overall experience.
You can use an interactive walkthrough system to help users acclimate to the product's features, and you can help them better understand why your product works for them.
Get the Word Out
Many free trials flop because consumers simply need to learn about the product.
For this reason, it’s essential to aggressively market your free trial option and get the word out in whatever way you can.
Advertising for a free trial increases the chances that consumers will see and opt for your product. Even if the free trial doesn’t work out, you will have collected valuable demographic information from the consumer.
Embed Surveys
Feedback paves the road to improvement.
By embedding small feedback surveys into your software, you can show the user that you value their opinions and act upon the feedback you receive.
This can allow you to make valuable tweaks to the product along the way, improving the experience for the consumer.
Additionally, surveys can allow you to determine if you’ve targeted the right population. If a certain number of people don’t like the product, you may be marketing to the wrong group.
Personalize the Trial Experience
Personalization is one of the primary markers of a successful free trial. Users love a personalized experience, and you can quickly capitalize on the demographic information you receive upon signup.
Consider adjusting your onboarding emails so they are based on behavior. For example, if a user hasn’t taken action in purchasing your product, you can target them with an email campaign that helps to address misconceptions or issues.
Optimize Trial Parameters
If your free trial conversion rate is low, you may need to optimize the parameters of your free trial.
If you’ve chosen an opt-in trial, for example, but it isn’t working, aim for an opt-out free trial on the next round—or vice versa.
Your trial length also matters, and it affects your free trial conversion rate. Longer trials are more likely to give consumers more time to explore the product and decide. Additionally, a more extended trial allows your users to acclimate to using the product and creates an inherent demand for more.
Additionally, you can adjust how many features you’ve given customers to access. For example, if you are using a limited free trial but it isn’t working, you might consider choosing an unlimited free trial option to see how that works for you.
Encourage Upgrades
Sometimes your in-app marketing needs to be more subtle.
You can encourage consumers to pay for your product by nudging them with reminders about upgrades and free trial parameters.
For example, you can let users know when they are reaching the end of a free trial to let them know that they should pay for the product if they wish to continue to use it.
Frequently Asked Questions
Consider the following answers to our most frequently asked questions.
What is a good free trial rate?
A good FCR for an opt-in trial is roughly 18.2%, while the consensus for an opt-out trial is an average of 2.5%.
What other metrics to use with FCR?
When assessing your free trial conversion rate, you should also pay attention to your CAC, LTV ratio, and retention rate, as these can contribute to a clearer picture of your success.
Which is the best type of free trial?
The type of free trial with the highest conversion rate is the opt-out free trial.
Key Takeaways
The free trial conversion rate is the metric that lets you know how many of your free trial users opt for your paid product.
This SaaS metric is crucial because it allows you to determine the strength of your value proposition, assess customer interest, identify pain points, collect demographic information, and raise revenue.
You can enhance your free trial conversion rate by making the user interface accessible, personalizing your product, and offering strong customer support.
This guide allows you to optimize your free trial conversion rate to fit your particular revenue objectives.
Related Metrics & KPIs